
视频压缩是怎样实现的?视频压缩的基本原理
视频压缩是怎样实现的?视频压缩的基本原理
发布日期:2020-06-10 13:51
视频是利用人眼视觉暂留的原理,通过快速播放一系列的图片,使人眼产生运动的感觉。视频中一张图片对应一帧,视频参数中的帧率表示每秒的帧数,帧率25就表示每秒有25张图片。如果不压缩,视频文件会很大,不方便存储和传播。
视频压缩时要用一种压缩算法减少和去除视频的冗余信息(编码)。播放时,则需要应用对应的解压算法对视频进行还原(解码)。有时我们的视频播放器不能播放某个视频文件,就是因为播放器缺少对应的解码能力。
随着多媒体技术的发展,相继推出了很多压缩编码标准,主要有 M-JPEG、MPEG、H.26X 系列等,其中 H.264 是当前最流行的视频编码标准之一,压缩效率高,支持的播放场景广泛,不用当心哪个手机或播放器不支持。( 新的标准 H.265 压缩效率更高,不过未普及 )
M-JPEG
JPEG 是静止图片的压缩标准,就是我们平时压缩 .jpg 图片的标准。M-JPEG 源于 JPEG 的压缩技术,这种压缩方式单独完整地压缩每一帧,可进行精确到帧的编辑。但 M-JPEG 只对帧内的空间冗余进行压缩,不对帧间的时间冗余进行压缩,压缩效率不高。
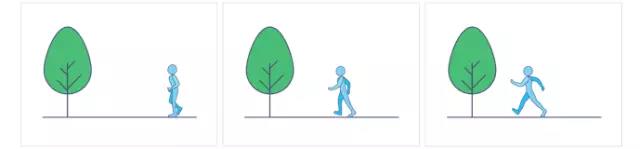
序列中的图像作为独立的图像进行压缩,彼此之间互不依赖
MPEG
MPEG 的基本原理是对比前后帧,第一帧被压缩图像将被用作参考,第二帧图像中只有与参考帧不同的部分才会被存储。播放时在参考帧图像和“差异数据”的基础上重建所有图像。这样的方法叫“差分编码”(包括H.264在内的大多数视频压缩标准都采用这种方法)。

差分编码示意,只有第一个图像信息是完整的,后面两个图像中静态分(树)将参考第一个图像,仅对运动部分( 走路的人 )使用运动矢量进行编码。减少存储的信息量。
相比 M-JPEG,MPEG 在帧内空间冗余和帧间的时间冗余上都进行压缩,压缩效率高。MPEG 目前有 MPEG-1、MPEG-2、MPEG-4 三个版本,以适应不同带宽和图像质量的要求。
我们常用的 H.264 也称为 MPEG-4 Part 10 或 AVC (高级视频编码),是 MPEG-4 系列标准中的一个新标准。在不影响图像质量的情况下,与采用 M-JPEG 和 MPEG-4 标准相比,H.264 编码器可以使视频文件大小分别减少80%和50%以上。
差分编码把视频的帧分成不同的类型,例如 I 帧、P 帧和 B 帧:
- I 帧 ( 关键帧,帧内压缩 )是一种自带完整图像信息的独立帧,无需参考其它图像便可独立进行解码,视频序列中的第一个帧始终都是I帧。I帧的缺点在于它们会占用更多的数据量,但I帧不会产生可觉察的模糊现象。
- P 帧 ( 差别帧 )只记录这一帧跟之前的一个关键帧(或P帧)的差别数据,解码时需要参考前一个关键帧(或P帧)画面加上本帧记录的差别,生成最终画面。与I帧相比,P帧通常占用更少的数据量,但由于P帧对前面的P和I参考帧有着复杂的依赖性,因此对传输错误非常敏感。
- B 帧 ( 双向差别帧 )也就是B帧记录的是本帧与前后帧的差别。B帧占用的数据量最少,对参考帧的依赖更强,要缓存后面的参考帧后才能进行解码取得最终画面。
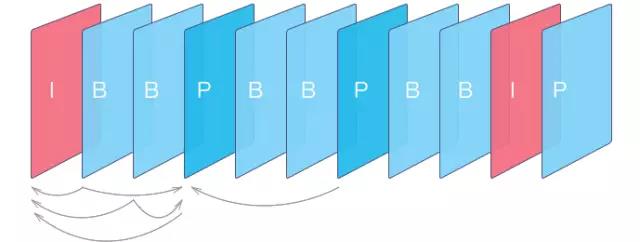
压缩后的视频会由这样的帧序列组成,带箭头的曲线表示了他们的参考关系。
I、B、P 各帧是根据压缩算法的需要,是人为定义的,它们都是实实在在的物理帧,至于图像中的哪一帧是I帧,是随机的,一但确定了I帧,以后的各帧就严格按规定顺序排列。
一般来说,I帧的压缩率是7%(跟 JPG 差不多),P 帧是20%,B 帧可以达到50%,可见使用 B 帧能节省大量空间,节省出来的空间可以用来保存多一些 I 帧,这样在相同码率下,可以提供更好的画质。
另外如果视频中存在大量物体运动的话,“差分编码” 将无法显著减少数据量 。这时 ,会采用基于块的运动补偿技术。因为视频序列中构成新帧的大量信息都可以在前面的帧中找到,但可能会在不同的位置上。所以 ,这种技术将一个帧分为一系列的块。然后,通过在参考帧中查找匹配块的方式 ,逐块地构建或者“ 预测 ”一个新帧 ( 例如 P 帧 )。如果发现匹配的块,编码器只需要对参考帧中发现匹配块的位置进行编码。与对整块的实际内容进行编码相比,只对块的运动信息进行编码可以减少所占用的数据量。